
3 de fev. de 2026
Como a IA Entende o Contexto de Consultas por Áudio

Transformar áudios em respostas claras e úteis é um desafio. Sotaques regionais, ruídos de fundo e a falta de contexto tornam difícil para a Inteligência Artificial (IA) interpretar mensagens de voz com precisão. Porém, tecnologias como reconhecimento automático de fala (ASR), processamento de linguagem natural (PLN) e análise de emoção estão mudando esse cenário.
Aqui está o que você precisa saber:
Por que é difícil: Mensagens de áudio têm ruídos, pausas, sotaques e emoções que dificultam a transcrição e interpretação.
Como a IA resolve: Modelos como Wav2Vec2 e Whisper melhoram transcrições, enquanto técnicas de PLN analisam o histórico da conversa para entender intenções.
Exemplo na prática: Empresas como QuintoAndar já usam IA para automatizar atendimentos com eficiência comparável a humanos.
Benefícios: Respostas mais rápidas (até 40% menos tempo), redução de erros e melhor experiência para o cliente.
O SacGPT, por exemplo, combina áudio, texto e dados históricos para oferecer um atendimento mais preciso e personalizado, integrando automação e suporte humano. Essa tecnologia é essencial para melhorar interações em plataformas como WhatsApp e Telegram, reduzindo o esforço manual e otimizando resultados.
O Problema: Por Que Consultas por Áudio São Difíceis de Interpretar
Ambiguidade da Fala e Sotaques Regionais
A fala espontânea no Brasil apresenta desafios únicos para sistemas de IA. Diferente de textos lidos ou preparados, as conversas reais trazem pausas, repetições e reinícios, dificultando a interpretação. Por exemplo, um modelo Distil-Whisper ajustado para o sotaque paulistano alcançou uma Taxa de Erro de Palavras (WER) de 24,22%, enquanto o modelo Wav2Vec2-XLSR-53 registrou 33,73% no mesmo cenário – uma diferença de quase 10 pontos percentuais.
Outro problema é a falta de dados de treinamento que representem a diversidade linguística brasileira. Até pouco tempo, havia somente cerca de 60 horas de áudio validado para o português brasileiro, enquanto o inglês contava com milhares de horas. Quando os modelos são treinados com dados mistos sem diferenciar sotaques, ocorre a chamada "interferência heterogênea", que prejudica o desempenho em sotaques específicos.
Região/Fonte | Tipo de Sotaque | Estilo de Fala |
|---|---|---|
São Paulo (Capital) | NURC-SP / SP2010 | Espontânea & Preparada |
São Paulo (Interior) | ALIP | Entrevistas Espontâneas |
Belo Horizonte | C-ORAL-BRASIL I | Informal & Espontânea |
Recife | NURC-Recife | Espontânea & Preparada |
Ruído de Fundo e Fala Emocional
Além dos desafios linguísticos, os ambientes reais trazem obstáculos como ruídos e variações emocionais. Por exemplo, a fala espontânea em português brasileiro apresenta uma Taxa de Erro de Palavras de 24,18% e de Caracteres de 11,02%, enquanto na fala lida esses números caem para 20,08% e 6,34%, respectivamente, usando o mesmo modelo.
"A degeneração de ruído devido à interferência de comunicação, que está quase sempre presente em transmissões de rádio, possui peculiaridades que uma simples formulação matemática não consegue modelar." - Julio Cesar Duarte e Sérgio Colcher
Outro ponto crítico é o viés dos modelos em favor da semântica textual em detrimento de pistas acústicas. Em casos de "fala emocionalmente incongruente" – quando as palavras expressam uma emoção e o tom vocal expressa outra – os sistemas priorizam o significado literal das palavras, ignorando o estado emocional do cliente. Isso pode levar a interpretações erradas sobre a urgência ou insatisfação do interlocutor.
Ausência de Contexto Visual
A falta de elementos visuais agrava ainda mais a ambiguidade em consultas por áudio. Sem pistas visuais, a IA tem dificuldade para resolver ambiguidades linguísticas básicas. Por exemplo, em português, palavras como "cobra" podem ser um substantivo (animal) ou um verbo (cobrar), e o significado correto geralmente depende do contexto situacional que pistas visuais ajudariam a esclarecer. Além disso, sarcasmo e ironia – comuns em interações de atendimento – são frequentemente transmitidos por expressões faciais ou gestos.
"O processo de anotação de discurso de ódio é intrinsecamente desafiador, considerando que o que é considerado ofensivo é fortemente influenciado por fatores pragmáticos (culturais), e as pessoas podem ter opiniões diferentes sobre uma ofensa." - Francielle Vargas, Pesquisadora, Universidade de São Paulo
Para melhorar a precisão dos modelos em cenários reais, é essencial uma documentação linguística que inclua pausas, entonação, hesitações e sobreposição de fala. Sem essa camada extra de informação, sistemas baseados apenas em áudio enfrentam grandes limitações na interpretação da intenção do cliente.
Inteligência Artificial para Transcrição de Áudio com Whisper Open AI | IA na Prática #01
Como a IA Resolve os Problemas de Contexto em Áudio
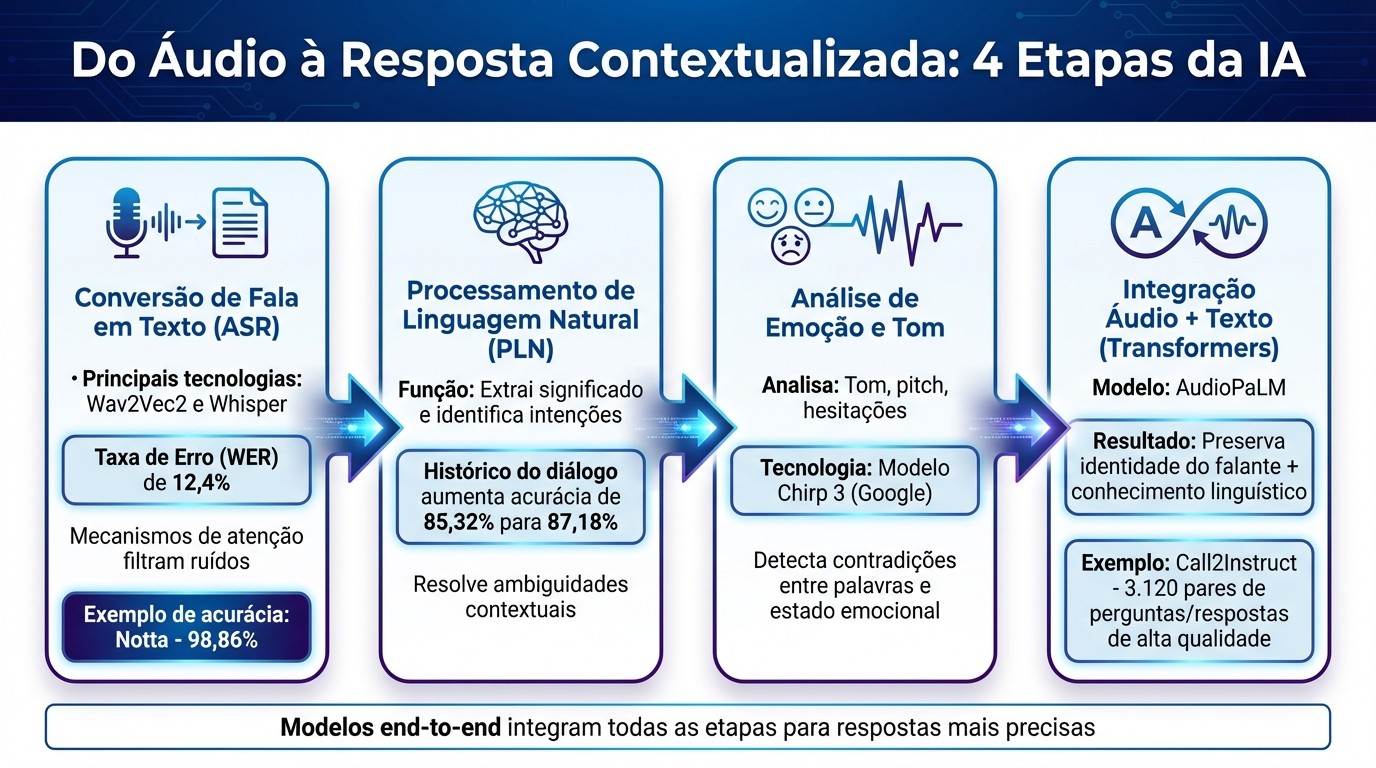
Como a IA processa consultas por áudio: do reconhecimento de fala à resposta contextualizada
Depois de compreender os desafios, é interessante observar como a tecnologia consegue superar essas barreiras. A IA moderna combina diferentes técnicas para transformar áudios complexos em respostas precisas e contextualizadas.
Convertendo Fala em Texto
Uma das bases para resolver os problemas de áudio é o uso de técnicas avançadas de reconhecimento de fala. Modelos como Wav2Vec2 e Whisper processam o áudio diretamente, sem a necessidade de extração manual de características. Esses modelos utilizam mecanismos de atenção para identificar padrões relevantes na fala, ignorando ruídos de fundo. Para lidar com sotaques regionais, eles são treinados com dados multilíngues e ajustados com corpora regionais, como o NURC-SP.
Os avanços na precisão são notáveis. Por exemplo, um modelo Wav2Vec 2.0 ajustado para o português brasileiro alcançou uma Taxa de Erro de Palavras (WER) de 12,4%, considerando sete conjuntos de dados diferentes. Ferramentas como a Notta relatam uma taxa de acurácia impressionante de 98,86%. Além disso, técnicas de análise espectral ajudam a filtrar ruídos, isolando os padrões relevantes.
Entendendo Contexto com Processamento de Linguagem Natural
Após a transcrição, entra em cena o Processamento de Linguagem Natural (PLN), que atua como o cérebro do sistema ao extrair significado do texto e identificar intenções. A diferença dos modelos modernos é sua capacidade de considerar o histórico do diálogo, o que ajuda a resolver ambiguidades.
Um exemplo prático vem de um estudo da Universidade de Campinas, que mostrou que a acurácia subiu de 85,32% para 87,18% ao incluir o histórico do diálogo, alcançando um F1-Score de 87,28%. Isso significa que perguntas vagas como "Está com preço bom?" passam a fazer sentido quando o sistema lembra que, momentos antes, o cliente estava perguntando sobre um produto específico.
"A análise de uma declaração para identificar a intenção de um usuário em um sistema de diálogo pode se beneficiar do contexto da conversa." - Jeanfranco D. Farfan-Escobedo, Instituto de Computação, Universidade de Campinas
Essa compreensão textual também abre caminho para a identificação do tom emocional na fala.
Detectando Emoção e Tom
A IA vai além do conteúdo textual, analisando aspectos emocionais da comunicação. Ela avalia tom, pitch e hesitações para captar emoções. Isso é essencial para interpretar se um cliente está frustrado, surpreso ou satisfeito – algo que o texto isolado não revela. O modelo Chirp 3 do Google, por exemplo, incorpora hesitações e entonações humanas para criar interações mais naturais e empáticas.
Essa análise acústica é combinada com o PLN para uma interpretação mais completa. Por exemplo, quando um cliente diz "tudo bem" com um tom irritado, o sistema identifica a contradição entre as palavras e o estado emocional, priorizando o tom real sobre o significado literal.
Combinando Áudio e Texto com Modelos Transformer
A integração de áudio e texto eleva a compreensão contextual. Modelos como o AudioPaLM combinam grandes modelos de linguagem baseados em texto com modelos de fala em uma única arquitetura. Isso permite que o sistema aproveite o vasto conhecimento linguístico dos modelos de texto, ao mesmo tempo em que preserva informações do áudio, como a identidade do falante e a entonação.
"AudioPaLM herda a capacidade de preservar informações paralinguísticas como identidade do falante e entonação do AudioLM e o conhecimento linguístico presente apenas em grandes modelos de linguagem de texto como o PaLM-2." - Paul K. Rubenstein et al., Pesquisadores
Um exemplo prático dessa fusão é o pipeline Call2Instruct, desenvolvido pela Universidade Federal de Goiás em janeiro de 2026. Usando mais de 3.000 gravações de chamadas de clientes do setor de telecomunicações, eles ajustaram um modelo Llama 2 7B com o text-embedding-ada-002 da OpenAI para vetorização semântica e Elasticsearch para buscas de similaridade. O resultado foi a criação de 3.120 pares de perguntas e respostas de alta qualidade a partir de áudios não estruturados, mostrando que a correspondência semântica baseada em transformers pode transformar dados ruidosos de call centers em recursos úteis para treinamento.
Diferente dos sistemas em cascata, os modelos end-to-end alternam entre áudio e texto e utilizam o contexto anterior da conversa de forma integrada, garantindo respostas mais precisas. Essa abordagem evita a perda de nuances durante a transcrição, tornando o atendimento ao cliente cada vez mais eficiente.
Como o SacGPT Processa Consultas por Áudio no Atendimento ao Cliente
Depois de superar os desafios de transcrição e análise contextual, o SacGPT utiliza essas tecnologias avançadas para transformar mensagens de voz em um atendimento eficiente e contextualizado, combinando automação inteligente com suporte humano sempre que necessário.
Processando Áudio em Múltiplos Canais
O SacGPT é capaz de lidar com consultas de áudio em plataformas como WhatsApp e Telegram, proporcionando uma experiência fluida e integrada. Ele transcreve automaticamente as mensagens de voz, permitindo que os atendentes leiam as consultas em texto, sem precisar ouvir arquivos longos. Isso reduz drasticamente o tempo de resposta.
A transcrição automática elimina o esforço manual de ouvir e interpretar áudios. Alianderson, da CertFaz, compartilha sua experiência: "A ferramenta de transcrição de áudio me ajudou muito a acelerar o atendimento. Antes, tínhamos que ouvir os áudios para localizar o que o cliente disse; agora a informação está toda em texto". Empresas que adotam IA no atendimento relatam uma redução de até 40% nos tempos de resposta, o que é crucial, já que 67% dos consumidores consideram o tempo de resposta um dos fatores mais importantes na experiência de serviço. A seguir, veja como o SacGPT aplica cada etapa desse processo na prática.
Usando Base de Conhecimento e Busca em Tempo Real
Após converter o áudio em texto, o SacGPT combina a transcrição com sua base de conhecimento integrada e ferramentas de busca em tempo real para criar respostas precisas. Com o suporte da ferramenta Copilot, o sistema acessa diretamente a base de dados da empresa para sugerir respostas consistentes e padronizadas.
Quando a interação é vaga, a IA solicita mais informações antes de acionar um atendente humano. Além disso, o SacGPT utiliza dados estruturados do histórico do cliente – como status de cadastro e interações anteriores – para prever com mais precisão o motivo do contato e encaminhar a consulta ao setor mais adequado.
Transferindo Casos Complexos para Atendentes Humanos
Em situações que exigem intervenção humana, o SacGPT transfere o caso com todo o contexto necessário. Ele gera um resumo automático que fornece ao atendente um panorama completo da interação. Gabriel Wagner, da Alfacrux Assessoria Contábil, comenta:
"O resumo automático e a transcrição fiel do áudio fornecem mais segurança e clareza no atendimento. Simples e fenomenal!"
A análise de sentimento, baseada em IA, identifica sinais de frustração ou irritação nas mensagens de áudio, alertando automaticamente quando a intervenção humana é necessária. Após a transferência, o chatbot é "silenciado" para evitar que respostas automáticas interfiram na interação com o atendente. Essa abordagem híbrida reduz o número médio de mensagens por ticket – de 18,2 mensagens (com triagem humana) para 14,2 mensagens (com triagem por IA) – e garante que os clientes não precisem repetir informações, resolvendo problemas de contexto de forma eficiente.
Benefícios e Etapas de Implementação
Respostas Mais Rápidas e Precisas
Com a transcrição automática, não é mais necessário escutar longos áudios para atender solicitações, o que reduz o tempo de resposta em até 40%. Essa agilidade não só otimiza o trabalho das equipes como também melhora a experiência do cliente, já que rapidez no atendimento é um dos fatores mais valorizados pelos consumidores.
Modelos ajustados para o português brasileiro, como o BERTaú desenvolvido pelo Itaú, mostram resultados impressionantes: um aumento de 2,1% na análise de sentimento e 4,4% no reconhecimento de entidades nomeadas em comparação com modelos multilíngues. Para lidar com sotaques regionais, versões otimizadas do Distil-Whisper apresentam taxas de erro de apenas 24,22%, garantindo transcrições confiáveis mesmo com variações linguísticas. Além disso, o uso de ferramentas de IA pode economizar até 17,5 horas por dia para equipes de suporte, somando mais de 350 horas por mês.
Escalabilidade para Diferentes Portes de Negócio
Outra vantagem significativa é a flexibilidade para atender empresas de diferentes tamanhos. Por exemplo, o SacGPT oferece planos que se ajustam às demandas específicas:
Plano Básico: R$ 120/mês, ideal para pequenos negócios, com até 10 conversas diárias.
Plano Ultra: R$ 610/mês, voltado para grandes operações, com suporte para até 250 conversas diárias.
Ambos os planos incluem funcionalidades como transferência para atendentes humanos, busca em tempo real e integração com a base de conhecimento. Caso o limite de conversas seja excedido, há um custo adicional de R$ 2,60 por conversa extra.
Empresas como o QuintoAndar já demonstraram o potencial dessa tecnologia. Ao processar 639.159 chats usando um chatbot baseado em BERT, a companhia conseguiu manter uma taxa de transferência para atendentes humanos de apenas 10,3% nos casos mais confiáveis. Com sistemas de IA, é possível automatizar até 80% das interações com clientes.
Configurando o Reconhecimento Multimídia
Para aproveitar ao máximo essas vantagens, é crucial configurar corretamente o reconhecimento multimídia. Isso inclui habilitar a transcrição automática de mensagens de voz no WhatsApp e Telegram, permitindo a conversão instantânea de áudio em texto. Além disso, ativar o recurso de Resumo Inteligente ajuda a condensar interações longas, fornecendo contexto imediato para os atendentes.
A integração com a base de conhecimento da empresa também é fundamental. Isso permite que o Copilot acesse informações relevantes para sugerir respostas consistentes e precisas. O processo completo envolve várias etapas técnicas, como:
Pré-processamento (redução de ruído e separação de canais);
Reconhecimento Automático de Fala (ASR);
Normalização textual;
Anonimização de dados para atender às exigências da LGPD.
Essas configurações garantem que a solução funcione de forma eficiente e em conformidade com as regulamentações.
Conclusão
Interpretar consultas por áudio não é tarefa simples. Sotaques variados, ruídos de fundo e ambiguidades exigem que a IA combine ferramentas como redução de ruído, reconhecimento automático de fala (ASR), análise de sentimento e processamento de linguagem natural (PLN), além de modelos especializados, como o BERT.
O SacGPT coloca essas tecnologias em prática no atendimento ao cliente. A plataforma processa mensagens de áudio enviadas por canais como WhatsApp e Telegram, transcrevendo-as automaticamente e enriquecendo o contexto com dados estruturados do histórico do cliente. Isso garante um atendimento contínuo e personalizado, mesmo em situações mais complexas.
Pesquisas mostram que essa tecnologia não apenas acelera o atendimento – com respostas até 40% mais rápidas – mas também melhora a eficiência operacional, liberando mais de 350 horas por mês para outras atividades. Um exemplo é o QuintoAndar, que conseguiu automatizar completamente a triagem de chats, mantendo uma taxa de transferência para atendentes humanos de cerca de 13% nos casos mais confiáveis. Esses resultados destacam como a IA pode oferecer respostas rápidas e consistentes, otimizando o atendimento.
Com 67% dos consumidores considerando o tempo de resposta um fator essencial para uma boa experiência de atendimento, a interpretação contextual de áudios passou de um diferencial para uma necessidade estratégica. Ao superar os desafios da compreensão de áudio, essa tecnologia transforma o atendimento ao cliente, combinando velocidade, precisão e empatia digital. Assim, torna-se possível oferecer um serviço escalável e altamente personalizado, colocando o cliente no centro de todas as interações.
FAQs
Como a IA consegue entender diferentes sotaques regionais em consultas por áudio?
A inteligência artificial consegue compreender diferentes sotaques regionais brasileiros graças a modelos avançados de reconhecimento de fala. Esses modelos são treinados com uma ampla variedade de dados de áudio que refletem as características de sotaques como o paulista, o carioca e o nordestino. Esse processo permite que a IA identifique as particularidades fonéticas de cada região, aumentando a precisão na interpretação das consultas feitas pelos usuários.
Além disso, técnicas como o fine-tuning - que ajusta os modelos com dados específicos de determinados sotaques - ajudam a capturar variações na pronúncia e no ritmo da fala. Isso significa que, independentemente do sotaque, a IA pode interpretar as consultas de maneira clara e eficaz, oferecendo uma experiência mais acessível e eficiente para todos.
Como o SacGPT ajuda a aprimorar o atendimento ao cliente no WhatsApp?
O SacGPT transforma o atendimento ao cliente no WhatsApp ao reunir diferentes canais de comunicação em um só lugar, tornando a gestão mais prática e organizada. Com o uso de inteligência artificial, a plataforma automatiza tarefas repetitivas, responde de forma rápida e personalizada e, quando necessário, direciona o atendimento para um humano.
Outro destaque é a capacidade do SacGPT de reconhecer mensagens multimídia, integrar bases de conhecimento e criar fluxos automatizados de mensagens. Esses recursos garantem um suporte mais rápido e próximo, melhorando a satisfação do cliente e ajudando a equipe a economizar tempo.
Quais são as vantagens de usar IA para entender emoções em mensagens de áudio?
A aplicação de IA para interpretar emoções em mensagens de áudio traz uma série de vantagens. A tecnologia examina elementos da voz, como tom, ritmo e intensidade, para reconhecer emoções como alegria, tristeza, nervosismo e medo. Isso abre caminho para interações mais naturais e empáticas entre pessoas e máquinas.
Esse recurso é particularmente valioso em setores como o atendimento ao cliente, onde entender o estado emocional do usuário pode levar a respostas mais personalizadas. Na área da saúde, a tecnologia pode ser usada para acompanhar o bem-estar emocional de pacientes, oferecendo suporte mais direcionado. A IA, assim, contribui para interações mais eficazes e ajustadas às necessidades de cada indivíduo.